Início
Início


Introdução
Nos últimos anos, as redes de computadores e telecomunicação sofreram inúmeras transformações. Com os crescentes avanços nas áreas tecnológicas, contribuíram para o desenvolvimento de sistemas de transmissão de dados com alto desempenho.No final dos anos 90, foi introduzida no mercado mundial a tecnologia MPLS (Multi Protocol Label Switching), onde se permitiu controlar a forma com que o tráfego flui através das redes IPs, otimizando o desempenho da rede e também melhorando o uso dos seus recursos.
Em redes IPs tradicionais, o encaminhamento dos pacotes, requer uma pesquisa que compara o endereço de
destino do pacote com cada uma das entradas na tabela de roteamento, encaminhando cada um para a saída
correspondente. Esse procedimento é repetido a cada nó percorrido ao longo do caminho, da origem ao destino. Isso de fato parece relativamente simples, porém, considerando que cada equipamento processa
milhares e as vezes milhões de pacotes por segundo, essa tarefa pode sobrecarregar a rede.
O MPLS é uma tecnologia de encaminhamento de pacotes baseada em rótulos que vem sendo adotado por operadoras para oferecer serviços diferenciados com eficiência nos transportes de dados. Os produtos oferecidos por operadoras baseados em MPLS, permitem disponibilizar não apenas velocidade de conexão, mas também a diferenciação de tráfego como Multimídia (Voz, Vídeo) e aplicações críticas, com garantias aplicáveis de QoS (Quality of Service), através das classes de serviço.
Atualmente o MPLS é um passo fundamentalpara a escalabilidade da rede, considerado essencial para um novo modelo de Internet no século XXI. MPLS é relativamente jovem, porém vem sendo implantada com êxito em redes de grandes operadoras de serviços em todo mundo.
Nesse trabalho será abordada a utilização de VPN camada 3 em redes MPLS como solução na segmentação de redes e segregaçãode tráfego, provendo aos assinantes/clientes das operadoras de serviço a interligação de estações distribuídas em uma ampla área geográfica de maneira rápida e seguras.
Objetivos
Os objetivos deste trabalho foram divididos em objetivo geral e objetivos específicos.
O objetivo geral é implementar uma solução de VPN de camada 3 em redes MPLS, utilizando emuladores como ferramenta de teste para demonstrar o desempenho e analise comparativa com outros tipos de redes.
Entre os objetivos específicos, destacam-se:
Abrangência
Propõe-se realizar um projeto de rede onde uma estrutura MPLS será montada, configurada e analisada através do uso de softwares, bem como emuladores de rede, emuladores de Sistemas Operacionais e sniffers
O simulador de rede usado emula os IOS (Internetwork Operating System) que são os softwares que rodam em roteadores da linha Cisco Systems, sendo que cada equipamento opera como uma máquina real, com acesso a todas as funcionalidades e protocolos, podendo comportar uma topologia de rede ampla em um único computador. Nessa estrutura serão estudadas as formas de roteamento que os backbones (operadoras) usam para comunicar-se com outros backbones e roteadores de assinantes (clientes) – CPE (customer premises equipment), tendo como foco principal do trabalho, mostrar e analisar o desempenho e vantagem da utilização de VPNs de camada 3 em redes MPLS através de nuvem privada.
A nuvem privada é a forma utilizada por operadoras de serviço para interligar vários pontos de uma mesma organização isolando o tráfego da nuvem pública a qual todos têm acesso. As análises serão executadas através da utilização de softwares específicos para o monitoramento de rede, capturando dados e posteriormente a gerando gráficos e relatórios. Assuntos como QoS, Engenharia de Tráfego, VPN de camada 2 e segurança não serão aprofundados, como também não serão implementadas soluções MPLS para a internet pública.
Para esse estudo será utilizado o programa GNS3 versão 0.7.2, um programa gratuito resultado de um projeto open source que pode ser utilizado em diversos sistemas operacionais como Windows, Linux e MacOS X. Com o GNS3 pode-se fazer praticamente tudo o que é possível fazer com roteadores e pix da linha Cisco. O GN3 é um gerenciador gráfico que está ligado diretamente a outros 3 softwares: Dynamips: o núcleo do programa que permite a emulação Cisco IOS. Dynagen: um texto baseado em front-end para o Dynamips.
Qemu: uma máquina de fonte genérica e aberta emulador e virtualizador.
Este programa é um emulador e não um simulador, pois utiliza as mesmas imagens binárias dos equipamentos reais, proporcionando assim, num local que já possua estes equipamentos, a possibilidade de testar uma nova
versão do IOS antes mesmo de colocá-lo nos equipamentos reais.
A motivação do uso desse software nesse TCC, se deu principalmente por ser gratuito e permitir utilizar os mesmos IOS dos roteadores, criando um ambiente de simulação que se aproxima bastante do ambiente real.
Para virtualização dos sistemas operacionais será utilizado o Virtual Box na versão 3.2.8. Virtual Box é um software de virtualização desenvolvido pela Oracle para arquiteturas de hardware x86 também gratuito, que visa criar ambientes para instalação de sistemas distintos. Ele permite a instalação e utilização de um sistema operacional dentro de outro em pleno funcionamento, assim como seus respectivos softwares, com dois ou
mais computadores independentes simultaneamente, compartilhando fisicamente o mesmo hardware.
O sistema operacional que será virtualizado no Virtual Box para gerar o tráfego nos ambientes do GNS3 será o Ubunto na versão 10.4. Ubuntu é um sistema operacional de código aberto mais popular do mundo na atualidade. Desenvolvido para notebooks, desktops e servidores, ele contém todos os aplicativos que qualquer outro sistema operacional tem, em versões similares e livre de licenças.
Para análise do tráfego de rede será utilizado o Wireshark. O é um programa que verifica os pacotes transmitidos pelo dispositivo de comunicação (placa de rede, placa de fax modem, etc.) do computador. O propósito deste tipo de software, também conhecido como sniffer, é detectar problemas de rede, conexões suspeitas, auxiliar no desenvolvimento e resolução de problemas. O programa analisa o tráfego de pacotes recebidos e organiza-os por protocolo. Todo o tráfego de entrada e saída é analisado e exibido em um ambiente gráfico de fácil visualização contribuindo para a explicação dos casos.
Metodologia
Para a realização deste trabalho serão adotados os seguintes procedimentos:
Tutoriais
Este tutorial parte I apresenta inicialmente os conceitos sobre Redes de Computadores, e a seguir os conceitos das Redes IP MPLS, e finaliza apresentando a parte I do modelo conceitual utilizado neste trabalho, relativa à configuração básica do MPLS com o protocolo OSPF.
O tutorial parte II apresentará as parte II (configuração do BGP/MPLS VPN) e III (configuração do IPsec em Redes IP) do modelo conceitual, a seguir apresentará a análise comparativa desses modelos, e finalizará com os resultados alcançados.

Camada Física
A primeira camada trata dos meios de transmissão físicos tais como: cabo metálico, fibra óptica e ondas de rádio. É responsável pela definição de um bit (um dígito binário 1 ou 0). Como exemplo, poderíamos ter uma situação em que a presença de uma tensão na linha por certo período fosse conhecida como “1” e a ausência de certa tensão fosse interpretada como “0” (TITTEL, 2003).
Camada de Enlace
Também conhecida como link de dados, a camada de enlace é responsável pela ligação dos dados. Segundo Tittel (2003), a camada de enlace converte os dados brutos e não confiáveis oriundos da camada física, num link confiável para a camada imediatamente acima (a camada de rede). Nesse processo os dados das camadas superiores, são encapsulados e transmitido pelo meio físico. Para isso um conjunto de regras é definido através do: controle erro, fluxo e atribuição de endereço físico aos dispositivos integrantes no enlace.
Camada de Rede
Camada responsável pelo encaminhamento do pacote da origem ao seu destino. Há
dois tipos de protocolos de camada 3: protocolos de roteamento e
protocolos roteáveis. Os primeiros são responsáveis pelo encaminhamento e os últimos em prover um caminho livre de ida e volta através da rede (TITTEL, 2003). IP, IPX e AppleTalk são os protocolos roteáveis enquanto RIP, OSPF, BGP exemplos de protocolos de roteamento.
Fazendo uma analogia com nosso cotidiano, os pacotes seriam as cartas e os protocolos de roteamento as operadoras de serviços postais.
Camada de Transporte
A camada de transporte ou camada 4 é responsável pela transferência eficiente, confiável e econômica dos dados entre um host de origem até seu destino. A função básica da camada de transporte é aceitar dados da camada acima, repassar essas unidades a camada de rede e assegurar que todos os fragmentos chegarão corretamente à outra extremidade (TANENBAUM, 2006).
Camada de Sessão
Essa camada tem como objetivo sincronizar o diálogo e gerenciar a troca de dados entre diferentes pontos da camada de apresentação. Segundo Tanenbaum (2006), a camada de sessão permite que os usuários de diferentes máquinas estabeleçam sessões entre eles.
Para Torres (2001, p. 44), “Um exemplo comum é a conversão do padrão de caracteres (código de página) quando, por exemplo, o dispositivo transmissor usa um padrão diferente do ASCII.”.
Conforme Colcher (et al., 2005, p. 61), “Da camada de sessão para cima, os serviços oferecidos começam a ficar bastante voltados ao fornecimento de facilidades para aplicações”. Pontos de sincronização e o gerenciamento de atividades são os principais exemplos dessas facilidades.
Camada de Apresentação
A Camada de Apresentação é responsável pela tradução para um formato padronizado ex: JPEG, MP3, ASCII. Essa camada também é responsável pela criptografia e decifração com objetivos de segurança, bem como compressão de dados segundo (Tittel, 2003). Nela são fornecidos os serviços que podem ser selecionados posteriormente pela camada de aplicação com a finalidade de interpretar a sintaxe dos dados trocados, resolvendo problemas de diferença de sintaxe entre sistemas abertos.
Camada de Aplicação
Essa é a camada que fornece uma interface para os usuários e é responsável pela formatação dos dados antes que eles sejam passados para as camadas inferiores (McHOES, 2002). Podemos citar como exemplos comuns nessa camada o correio eletrônico e transferências de arquivos. Segundo Tanenbaum (2003, p.47), “A camada de aplicação contém uma série de protocolos comumente necessários para os usuários”.
Para Colcher (et al., 2005, p. 62), “Nesse nível são definidas funções de gerenciamento e mecanismos genéricos que servem de suporte à construção de aplicações distribuídas”.
Arquitetura TCP/IP
TCP/IP (Transmission Control Protocol / Internet Protocol) também chamado de pilha de protocolo TCP/IP, fornece um conjunto de serviços definidos para protocolos das camadas superiores. Segundo Colcher (et al., 2005, p. 70), “Os protocolos da Arquitetura TCP/IP, oferecem uma solução simples, porém bastante funcional, para o problema da interconexão de sistemas abertos”.
Assim como o modelo OSI, a Arquitetura TCP/IP é dividida em camada. A camada de Aplicação é correspondente às camadas 7, 6 e 5 do modelo OSI. A camada Host-to-host, espelha as funções da camada de transporte do modelo OSI. A camada de Rede, que corresponde a mesma camada de rede do modelo OSI, e por fim, a camada de Acesso à Rede, equivalente as camadas 1 e 2 do modelo OSI (FILLIPETTI, 2008).
Protocolo IP
O protocolo IP (Internet Protocol) definido pela RFC 791, conforme Postel (2002) é a base ou suporte para os outros protocolos da pilha TCP/IP, tais como ICMP, UDP e TCP, que são transmitidos em data gramas IP.
Uma característica deste protocolo é a possibilidade de fragmentar e remontar datagramas, de modo que estes possam ser transmitidos entre redes que suportem diferentes tamanhos por bloco de dados. Foi projetado para prover as funções necessárias para entregar pacotes de bits (datagramas IP) de uma origem para um destino determinado.
O protocolo IP é baseado na entrega de datagramas sem garantias, portanto inclui um conjunto de regras que dizem como hosts e gateways devem processar os datagramas, quando e como uma mensagem de erro deve ser gerada e as condições nas quais datagramas devem ser descartados (Comer, 2007). Ele incorpora também a função de roteamento, isto é, determina se um datagrama deve ser entregue diretamente a seu destino, caso origem e destino pertençam á mesma rede ou ao contrário entrega ao gateway da rede, contendo os dados do pacote de origem. Na figura 2 é ilustrada o cabeçalho IP.
 Figura 2: Cabeçalho IP
Figura 2: Cabeçalho IP
Fonte: Stevens (1994, p. 34)
Endereçamento IPv4
O endereçamento IP, é uma identificação numérica atribuído a cada dispositivo conectado a uma rede IP, definindo para tal, uma localização na rede. No caso do IPv4 essa numeração tem o tamanho de 32 bits, onde a representação decimal é dividida em 4 blocos de 8 bits, o menor valor numérico em decimal de cada bloco é “0” e o maior igual à “255”, exemplo o endereço IP “72.247.64.170”.
Conforme Fillipetti (2008, p. 147), “A subdivisão de um endereço IP nas porções de rede e nó é determinada pela classe em que se encontra tal endereço”. Na figura 3, é ilustrada as cinco classes e os intervalos de endereços de cada uma.

Figura 3: Classe de endereços IP
Fonte: Fillipetti (2008, p. 147)
A divisão dos endereços IP’s em classes, facilita o processo de roteamento principalmente em grandes redes. A técnica consiste em verificar os primeiros dois bits do endereçamento, caso o primeiro bit for “0” o roteador tem a capacidade de encaminhar o pacote apenas com base nessa informação, sabendo-se que o endereço pertence à essa rede é de classe A, se for igual à “10” será de classe B e “11” classe C.
Entretanto, existem algumas faixas de numeração IP reservados, que não devem ser roteados na internet pública. Estas redes estão descritos na RFC 1918 (Address Allocation for Private Internets). A IANA (Internet Assigned Numbers Authority) tem reservado os seguintes blocos de IP para rede privada conforme a tabela 1.
Tabela 1: Blocos de endereços IPs Privados
Fonte: Elaboração do Autor, 2010
Portanto, uma empresa ou organização que precise de um IP ou uma faixa de IP público global para ter acesso externo à Internet, nunca receberá endereços atribuídos às faixas mostradas acima. Os endereços de classe D são reservados para o uso de comunicação em Multicast.
O Multicast é um método para entrega de dados para múltiplos destinatários, em um modelo de um para vários. Para Costa (2006, p. “Quanto um pacote é enviado para um endereço Multicast, todos os host que fazem parte desse grupo Multicast receberão esse pacote”. Protocolos de roteamento usam esse método para descobrir roteadores pertencentes ao grupo na rede.
Protocolo ARP e RARP
O protocolo ARP (Address Resolution Protocol) definido pela RFC 826, conforme Torres (2001), foi projetado para interfaces do tipo 10 Mega bit Ethernet, mas foi generalizado para outros tipos de hardware. O módulo de resolução de endereços, normalmente parte do driver do dispositivo de hardware, recebe um par e tenta encontrá-lo em uma tabela. Se o par for encontrado, é retornado o endereço do hardware ou endereço físico correspondente para que o pacote possa ser transmitido. Caso contrário é normalmente informado que o pacote será descartado. Um exemplo comum na Internet é a utilização do ARP para converter endereços IP, de 32 bits, em endereços Ethernet, de 48 bits.
A função do protocolo RARP (Reverse Address Resolution Protocol) definido pela RFC 903, é inversa ao ARP, ou seja, converte um endereço de físicos em um endereço Internet. No momento da inicialização RARP é usado para encontrar o endereço Internet correspondente ao endereço de hardware do nó.
Protocolo ICMP
O protocolo ICMP (Internet Control Message Protocol) segundo Postel, (2002) tem como finalidade relatar erros no processamento de datagramas IP, bem como prover mecanismos de investigação nas características gerais de redes TCP/IP. O protocolo ICMP é definido na RFC 792.
As mensagens ICMP são enviadas em datagramas IP. Embora o ICMP pareça fazer parte do conjunto de protocolos de nível mais alto, este é parte da implementação do protocolo IP. O formato do cabeçalho de uma mensagem ICMP é apresentado na figura 4.

Figura 4: Formato de mensagens ICMP
Fonte: Stevens (1994, p. 70)Protocolo UDP
O protocolo UDP (User Datagram Protocol) Postel (2002) provê um mecanismo não orientado a conexão, ou seja, sem garantias, que através da utilização do protocolo IP, envia e recebe datagramas de uma aplicação para a outra. São utilizados números de portas para distinguir entre várias aplicações em um mesmo host, ou seja, cada mensagem UDP contém uma porta de origem e uma porta de destino.
Uma aplicação baseada no protocolo UDP é inteiramente responsável por problemas de confiabilidade e problemas relacionados á conexão. Como isto normalmente não ocorre, este protocolo tem grande funcionalidade em ambientes locais e em aplicações que não requerem alta confiabilidade (Comer, 2007). Na figura 5 é demonstrada o modelo do cabeçalho UDP.
O TCP (Transmission Control Protocol) conforme Postel (2002) é um protocolo de comunicação que provê conexões entre máquinas, de forma confiável, ou seja, é um protocolo orientado á conexão. Segundo Stevens (1994), o termo orientado á conexão "significa que duas aplicações, usando um protocolo que detém esta característica, devem estabelecer uma conexão bidirecional, antes de efetuar troca de dados”.
É considerado um protocolo confiável, pois quando um host envia dados a outro, o primeiro exige o reconhecimento relativo á chegada dos dados. Os dados são seqüenciados de forma que um número é associado a todo pacote transmitido, permitindo assim, que os dados sejam reordenados caso recebidos fora de ordem e descartando caso haja duplicações de pacotes já recebidos.
O controle de fluxo é uma característica importante, permitindo em uma conexão, que o host sempre informe ao outro quantos bytes poderão ser aceitos, evitando assim a ocorrências de sobrecargas do buffer do host que estiver recebendo dados (Stevens, 1994).

Roteamento
O roteamento é a forma usada pelas redes de comutadores para realizar entrega de pacotes entre hosts (computadores, servidores, roteadores.), através de um conjunto de regras que definem como dados originados em uma determinada sub-rede devem alcançar outra. De uma forma geral a internet é uma teia de roteadores interligados onde cada um é responsável por entregar o pacote (caso o destino esteja em sua rede) ou encaminhar ao próximo roteador.
Conforme Tittel (2003) o roteador precisa primeiramente saber quantas portas físicas (ethernet, serial, bri, pri..) e quais são os endereços de rede configurado em cada uma delas. Essas informações são fundamentais para o roteador montar sua tabela de roteamento e saber se o pacote que está sendo processado está ou não em sua rede.
As formas de roteamento mais comum dentre os roteadores de ponta ou CE é o estático e entre os roteadores de borda PE e de núcleo P os dinâmicos. O roteamento dinâmico é dividido em IGP (Interior Gateway Protocol) e EGP (Exterior Gateway Protocol) que serão abordados nos próximos tópicos.
Roteamento Estático
Esse tipo de roteamento é usado pelo administrador quando se tem o conhecimento das redes nos quais os pacotes vão atingir. Tendo em vista que essa modalidade não se adapta á mudanças da rede, são geralmente usados em ponta de rede (cliente) ou em redes com poucos roteadores. Os valores tais como: rede, máscara de destino, gateway e custo, são configurados manualmente no roteador, onde os pacotes seguiram sempre a regra.
Segundo Comer (2007) nesse tipo de roteamento, uma tabela de roteamento estática é preenchida com valores quando o sistema é inicializado e elas só mudaram se o sistema vir á apresentar defeito. Essas tabelas são usadas para determinar para onde cada pacote deve ser encaminhado.
Os principais benefícios do roteamento estático são: redução de overhead, não utiliza largura de banda, já que não troca informações de roteamento e segurança, uma vez que o administrador possui o controle do processo de roteamento.
Roteamento Dinâmico
Para uma pequena rede ou em redes onde não há constantes mudanças, o roteamento estático pode ser usado, configurando manualmente cada uma das rotas. Já em redes maiores, configurar cada uma das rotas não é uma boa opção para o administrador. Em grandes redes normalmente é utilizado protocolos de roteamento dinâmicos, fazendo com que os roteadores troquem informações sobre roteamento e se adaptem melhor as mudanças de rede caso alguma eventualidade aconteça.
Segundo Filippetti (2008) o processo de roteamento dinâmico utiliza protocolos para encontrar e atualizar tabelas de roteamento de roteadores. Esse modo é muito mais fácil comparado ao roteamento estático, porém consome largura de banda e processamento da CPU do equipamento. Os protocolos de roteamento dinâmicos são classificados como: vetor á distância, link state e híbrido.
Protocolos de Roteamento Distance Vector
São classificados nessa categoria os protocolos de roteamento que utilizam distância à rede remota como métrica para a escolha caminho. É definido como a melhor rota aquela que conter o menor número de saltos ou hops como é chamada, até a rede remota, ou seja, são protocolos que se baseiam na contagem de saltos para definir a escolha da melhor rota. Exemplos de protocolos que pertencem a essa classe são RIP (Route Information Protocol) e IGRP (Interior Gateway Routing Protocol).
O funcionamento dos protocolos vetor á distância consiste em enviar as tabelas de roteamento aos roteadores vizinhos, combinando essas com outras que já possuem, montando um mapa da rede (Filippetti, 2008). Em caso de uma rede possuir vários links para uma mesma rede remota a distância administrativa é o primeiro fator a ser checado para definir a rota preferencial.
O RIP utiliza apenas a contagem de saltos (hop count) para determinação da melhor rota para uma rede remota. Se o RIP deparar-se com mais de um link para a mesma rede remota com a mesma contagem de saltos, ele executará automaticamente o que chamamos de round-robin load balance, ou seja, distribuirá alternadamente a carga entre os links de igual custo (mesmo número de saltos no caso). O RIP pode realizar balanceamento de carga para até 6 links com mesmo custo. (Filippetti 2008, p. 253)
Nesse caso pode ser uma solução ou um problema, já que o balanceamento entre os links será efetuado independentemente da velocidade de banda, ocasionando problemas de congestionamento quando a velocidade entre os links for diferente.
Outro exemplo é o IGRP (Interior Gateway Routing Protocol) segundo Enne (2009, p. 26), “É um protocolo proprietário definido pela CISCO Systems e representa a evolução do RIP, operando também distance vector”.
Protocolos de Roteamento Link-State
Os protocolos de roteamento link state são protocolos baseados no algoritmo Dijkstra SPF (Shortest Path First). Utilizado principalmente para comunicação dentro de um domínio de roteamento ou uma AS, esse algoritmo produz mais informações locais (dentro do próprio equipamento) sem a necessidade de ficar coletando informações sobre o estado da rede a todo o momento, os anúncios são feitos somente quando há mudança na rede, reduzindo assim o consumo de banda. Em contrapartida, esse tipo de roteamento eleva muito a carga de processamento, aconselhado, antes de implementá-lo, verificar se o hardware irá suportar tal demanda.
Os Protocolos de roteamento link state mantêm registro de todas as rotas possíveis para evitar alguns problemas típicos de protocolos vetor à distância como loops de roteamento. Os protocolos mais utilizados que se baseiam na tecnologia link-state são OSPF e IS-IS.
O OSPF (Open Shortest Path First) definido na versão atual pela RFC 2328, é um protocolo do tipo IGP projetado para trabalhar em grandes redes, atendendo as necessidades das nuvens públicas e privadas. O protocolo OSPF veio atender operadoras que demandavam de um protocolo IGP eficiente, versátil, de rápida convergência, interoperável com outros protocolos de roteamento e não proprietário, assim podendo ser incorporado a equipamentos de qualquer fabricante.
Trabalha com conceito de áreas ou grupo de roteadores que compartilham o mesmo ID de áreas. Segundo Brent (2008), o algoritmo Dijkstra SPF é usado para calcular o melhor caminho para o destino construindo caminhos sem loops com capacidade de convergência muito rápida. Habilitado nos roteadores, o OSPF constrói adjacências ao enviar pacotes hello através das interfaces. Os pacotes hello são responsáveis pela descoberta, estabelecimento e manutenção de relações entre roteadores vizinhos e são disparados pelo endereço multicast 224.0.0.5. Os roteadores que compartilharem um link comum e aceitarem os parâmetros dos pacotes hello, tornam-se vizinhos formando adjacências, caso contrário a negociação é desfeita. Assim que as adjacências são formadas, é envia uma LSA (Link State Advertisements) para os roteadores adjacentes. LSA´s são datagramas que descrevem os status de cada link e o estado de cada roteador, existem LSA para cada tipo de link.
Conforme Fillipetti (2008), o OSPF utiliza de mecanismos para eleger um DR (Designated Router) e um BDR (Backup Designated Router).
O Roteador DR é responsável por estabelecer adjacências com todos os vizinhos, enquanto o BDR fica de backup caso o DR venho à falhar, assumindo todas as suas funções. O escolha do roteador DR é determinada pelo maior valor de prioridade configurada. No caso das prioridades estarem configuradas com mesmo valor, a escolha do DR é feita pelo maior valor de IP da interface ativa e a segunda maior será o BDR, dando sempre preferência para os endereços das interfaces loopback. O endereço multicast 224.0.0.6 é usado para enviar informações ao DR, o BRD também recebe pacotes nesse endereço mais de maneira passiva.
Logo após todo o banco de dados da área correspondente rede estiver completo, cada roteador executa o algoritmo SPF e constrói sua tabela de roteamento formando a topologia da rede. Com base nesses cálculos os roteadores constroem suas link-state databese, onde fica armazenado o mapa completo de todos os roteadores, seus links e o estado de cada link. Muito utilizado em redes de alta performance, o OSPF é fundamental para empresas que busca desempenho em equipamentos que comportam grande capacidade de processamento.
O protocolo IS-IS (Intermediate System to Intermediate System) definido pela RFC 1142, é um outro exemplo de protocolo link-state tipo IGP, conhecido também como protocolo intra-domínio. É comumente usado para interligar roteadores em áreas distintas ou em mesma área, utiliza o algoritmo Dijkstra SPF com suporte a VLSM (Variable Length Subnet Mask) e rápida convergência assim como o OSPF. IS-SI e OSPF têm mais semelhanças do que diferenças. Ambos os protocolos foram desenvolvidos em torno do mesmo propósito, porém, entre os protocolos IGP, o OSPF é mais usado no momento (Enne, 2009).
Protocolo BGP
O BGP (Border Gateway Protocol) é um protocolo tipo EGP de maior utilização no momento. Para Enne (2009. p. 31) “É o protocolo distance vetor, baseado no paradigma que considera apenas os endereços de destino ou os prefixos dos endereços de destino como referência para roteamento e no número de hops atravessados para alcançar esses destinos”. O BGP é um protocolo de roteamento moderno e extremamente complexo, projetado para escalar as maiores redes e criar rotas estável entre elas, com suporte para comprimento variável máscara de sub-rede VLSM (Variable Length Subnet Mask) e roteamento intra-domínios sem classe CIDR (Classless Inter-Domain Routing) e compactação.
Na versão atual definida pela RFC 4271, o BGP é um amplamente difundido em toda a Internet e dentro de organizações multinacionais. Seu principal objetivo é conectar as grandes redes identificadas por uma AS (Autônomous Systems) ou sistemas autônomos. Um AS é uma rede ou um conjunto de redes que além de compartilharem uma gestão comum, possuem características e políticas de roteamento comuns. Utilizadas em protocolos de roteamento dinâmicos tipo EGP, servem para comunicar com outros equipamentos dentro de uma mesma AS e inter-AS.
No funcionamento básico, o BGP obtém as rotas referentes às redes pertencentes a uma AS, onde internamente são conduzidas por protocolos tipo IGP, e repassam para roteados BGPs vizinhos.
Considerando que os IGPs buscam as informações mais recentes que estão constantemente ajustando as rotas com base em novas informações, o BGP foi projetado para dar preferência as rotas mais estáveis e não constantemente renunciando. Além disso, configurações BGP normalmente requerem decisões políticas complexas. Assim, dado esta complexidade associada ao tamanho extremo da tabela de roteamento (muitas vezes centenas de milhares de rotas), não é surpreendente que as rotas que ficam constantemente ajustando poderiam sobrecarregar o BGP. (Brent, 2008, p. 399).
Conforme Enne (2009), o BGP utiliza o protocolo TCP para transporte as mensagens, aproveitando algumas facilidades nele contidas. Existem quatro tipos de mensagens BGP utilizados na formação de relacionamento entre vizinhos e manutenção: OPEN, KEEPALIVE, UPDATE e NOTIFICATION, onde começam a ser trocadas logo após o estabelecimento das conexões TCP.
Quando iniciado um processo BGP, ele cria ligações através de mensagens BGP OPEN e se aceitas, obtém uma resposta com KEEPALIVE. Estabelecido pela primeira vez, os roteadores BGP trocam suas tabelas de roteamento completas utilizando mensagens de UPDATE e posteriormente, enviadas quando houver alguma mudança na rede. Mensagens NOTIFICATION são enviadas para notificar algum erro, nessas condições, conexões BGP são encerradas imediatamente.
As rotas são controladas à medida que atravessam os roteadores BGP para evitar loops de roteamento. Consiste em rejeitar as rotas que já passaram por sua AS. A cada salto do pacote, é inserido o número da AS em AS-path, conforme a figura abaixo.

Figura 8: Uso de AS-Path para detecção de loops BGP
Fonte: Brent (2008, p. 400)
Nos últimos anos, as redes de computadores e telecomunicação sofreram inúmeras transformações. Com os crescentes avanços nas áreas tecnológicas, contribuíram para o desenvolvimento de sistemas de transmissão de dados com alto desempenho.No final dos anos 90, foi introduzida no mercado mundial a tecnologia MPLS (Multi Protocol Label Switching), onde se permitiu controlar a forma com que o tráfego flui através das redes IPs, otimizando o desempenho da rede e também melhorando o uso dos seus recursos.
Em redes IPs tradicionais, o encaminhamento dos pacotes, requer uma pesquisa que compara o endereço de
destino do pacote com cada uma das entradas na tabela de roteamento, encaminhando cada um para a saída
correspondente. Esse procedimento é repetido a cada nó percorrido ao longo do caminho, da origem ao destino. Isso de fato parece relativamente simples, porém, considerando que cada equipamento processa
milhares e as vezes milhões de pacotes por segundo, essa tarefa pode sobrecarregar a rede.
O MPLS é uma tecnologia de encaminhamento de pacotes baseada em rótulos que vem sendo adotado por operadoras para oferecer serviços diferenciados com eficiência nos transportes de dados. Os produtos oferecidos por operadoras baseados em MPLS, permitem disponibilizar não apenas velocidade de conexão, mas também a diferenciação de tráfego como Multimídia (Voz, Vídeo) e aplicações críticas, com garantias aplicáveis de QoS (Quality of Service), através das classes de serviço.
Atualmente o MPLS é um passo fundamentalpara a escalabilidade da rede, considerado essencial para um novo modelo de Internet no século XXI. MPLS é relativamente jovem, porém vem sendo implantada com êxito em redes de grandes operadoras de serviços em todo mundo.
Nesse trabalho será abordada a utilização de VPN camada 3 em redes MPLS como solução na segmentação de redes e segregaçãode tráfego, provendo aos assinantes/clientes das operadoras de serviço a interligação de estações distribuídas em uma ampla área geográfica de maneira rápida e seguras.
Objetivos
Os objetivos deste trabalho foram divididos em objetivo geral e objetivos específicos.
O objetivo geral é implementar uma solução de VPN de camada 3 em redes MPLS, utilizando emuladores como ferramenta de teste para demonstrar o desempenho e analise comparativa com outros tipos de redes.
Entre os objetivos específicos, destacam-se:
- Estudar a tecnologia MPLS;
- Estudar os tipos de roteamento;
- Estudar as VRFs (VPN Routing and Forwarding Table) em uma estrutura MPLS;
- Estudar os softwares utilizados na proposta;
- Configurar as tecnologias de redes estudadas nos softwares utilizados;
- Analisar o desempenho do funcionamento da implementação;
- Comparar com outras estruturas de redes convencionais.
Abrangência
Propõe-se realizar um projeto de rede onde uma estrutura MPLS será montada, configurada e analisada através do uso de softwares, bem como emuladores de rede, emuladores de Sistemas Operacionais e sniffers
O simulador de rede usado emula os IOS (Internetwork Operating System) que são os softwares que rodam em roteadores da linha Cisco Systems, sendo que cada equipamento opera como uma máquina real, com acesso a todas as funcionalidades e protocolos, podendo comportar uma topologia de rede ampla em um único computador. Nessa estrutura serão estudadas as formas de roteamento que os backbones (operadoras) usam para comunicar-se com outros backbones e roteadores de assinantes (clientes) – CPE (customer premises equipment), tendo como foco principal do trabalho, mostrar e analisar o desempenho e vantagem da utilização de VPNs de camada 3 em redes MPLS através de nuvem privada.
A nuvem privada é a forma utilizada por operadoras de serviço para interligar vários pontos de uma mesma organização isolando o tráfego da nuvem pública a qual todos têm acesso. As análises serão executadas através da utilização de softwares específicos para o monitoramento de rede, capturando dados e posteriormente a gerando gráficos e relatórios. Assuntos como QoS, Engenharia de Tráfego, VPN de camada 2 e segurança não serão aprofundados, como também não serão implementadas soluções MPLS para a internet pública.
Para esse estudo será utilizado o programa GNS3 versão 0.7.2, um programa gratuito resultado de um projeto open source que pode ser utilizado em diversos sistemas operacionais como Windows, Linux e MacOS X. Com o GNS3 pode-se fazer praticamente tudo o que é possível fazer com roteadores e pix da linha Cisco. O GN3 é um gerenciador gráfico que está ligado diretamente a outros 3 softwares: Dynamips: o núcleo do programa que permite a emulação Cisco IOS. Dynagen: um texto baseado em front-end para o Dynamips.
Qemu: uma máquina de fonte genérica e aberta emulador e virtualizador.
Este programa é um emulador e não um simulador, pois utiliza as mesmas imagens binárias dos equipamentos reais, proporcionando assim, num local que já possua estes equipamentos, a possibilidade de testar uma nova
versão do IOS antes mesmo de colocá-lo nos equipamentos reais.
A motivação do uso desse software nesse TCC, se deu principalmente por ser gratuito e permitir utilizar os mesmos IOS dos roteadores, criando um ambiente de simulação que se aproxima bastante do ambiente real.
Para virtualização dos sistemas operacionais será utilizado o Virtual Box na versão 3.2.8. Virtual Box é um software de virtualização desenvolvido pela Oracle para arquiteturas de hardware x86 também gratuito, que visa criar ambientes para instalação de sistemas distintos. Ele permite a instalação e utilização de um sistema operacional dentro de outro em pleno funcionamento, assim como seus respectivos softwares, com dois ou
mais computadores independentes simultaneamente, compartilhando fisicamente o mesmo hardware.
O sistema operacional que será virtualizado no Virtual Box para gerar o tráfego nos ambientes do GNS3 será o Ubunto na versão 10.4. Ubuntu é um sistema operacional de código aberto mais popular do mundo na atualidade. Desenvolvido para notebooks, desktops e servidores, ele contém todos os aplicativos que qualquer outro sistema operacional tem, em versões similares e livre de licenças.
Para análise do tráfego de rede será utilizado o Wireshark. O é um programa que verifica os pacotes transmitidos pelo dispositivo de comunicação (placa de rede, placa de fax modem, etc.) do computador. O propósito deste tipo de software, também conhecido como sniffer, é detectar problemas de rede, conexões suspeitas, auxiliar no desenvolvimento e resolução de problemas. O programa analisa o tráfego de pacotes recebidos e organiza-os por protocolo. Todo o tráfego de entrada e saída é analisado e exibido em um ambiente gráfico de fácil visualização contribuindo para a explicação dos casos.
Metodologia
Para a realização deste trabalho serão adotados os seguintes procedimentos:
- Revisão
Bibliográfica de todo assunto abordados no
projeto.
- Estudo das tecnologias de
redes.
- Estudo das técnicas de
roteamento.
- Estudo da topologia a ser
implementada.
- Estudo dos softwares a serem utilizados na
implementação
- Pesquisa dos equipamentos suportados pela
topologia.
- Levantamento das IOS (Internetwork Operating
System) dos equipamentos.
- Implementação da topologia nos
simuladores.
- Configuração dos equipamentos nos
simuladores.
- Descrever detalhes de analise e
desempenho.
Tutoriais
Este tutorial parte I apresenta inicialmente os conceitos sobre Redes de Computadores, e a seguir os conceitos das Redes IP MPLS, e finaliza apresentando a parte I do modelo conceitual utilizado neste trabalho, relativa à configuração básica do MPLS com o protocolo OSPF.
O tutorial parte II apresentará as parte II (configuração do BGP/MPLS VPN) e III (configuração do IPsec em Redes IP) do modelo conceitual, a seguir apresentará a análise comparativa desses modelos, e finalizará com os resultados alcançados.
Camada Física
A primeira camada trata dos meios de transmissão físicos tais como: cabo metálico, fibra óptica e ondas de rádio. É responsável pela definição de um bit (um dígito binário 1 ou 0). Como exemplo, poderíamos ter uma situação em que a presença de uma tensão na linha por certo período fosse conhecida como “1” e a ausência de certa tensão fosse interpretada como “0” (TITTEL, 2003).
Camada de Enlace
Também conhecida como link de dados, a camada de enlace é responsável pela ligação dos dados. Segundo Tittel (2003), a camada de enlace converte os dados brutos e não confiáveis oriundos da camada física, num link confiável para a camada imediatamente acima (a camada de rede). Nesse processo os dados das camadas superiores, são encapsulados e transmitido pelo meio físico. Para isso um conjunto de regras é definido através do: controle erro, fluxo e atribuição de endereço físico aos dispositivos integrantes no enlace.
Camada de Rede
Camada responsável pelo encaminhamento do pacote da origem ao seu destino. Há
dois tipos de protocolos de camada 3: protocolos de roteamento e
protocolos roteáveis. Os primeiros são responsáveis pelo encaminhamento e os últimos em prover um caminho livre de ida e volta através da rede (TITTEL, 2003). IP, IPX e AppleTalk são os protocolos roteáveis enquanto RIP, OSPF, BGP exemplos de protocolos de roteamento.
Fazendo uma analogia com nosso cotidiano, os pacotes seriam as cartas e os protocolos de roteamento as operadoras de serviços postais.
Camada de Transporte
A camada de transporte ou camada 4 é responsável pela transferência eficiente, confiável e econômica dos dados entre um host de origem até seu destino. A função básica da camada de transporte é aceitar dados da camada acima, repassar essas unidades a camada de rede e assegurar que todos os fragmentos chegarão corretamente à outra extremidade (TANENBAUM, 2006).
Camada de Sessão
Essa camada tem como objetivo sincronizar o diálogo e gerenciar a troca de dados entre diferentes pontos da camada de apresentação. Segundo Tanenbaum (2006), a camada de sessão permite que os usuários de diferentes máquinas estabeleçam sessões entre eles.
Para Torres (2001, p. 44), “Um exemplo comum é a conversão do padrão de caracteres (código de página) quando, por exemplo, o dispositivo transmissor usa um padrão diferente do ASCII.”.
Conforme Colcher (et al., 2005, p. 61), “Da camada de sessão para cima, os serviços oferecidos começam a ficar bastante voltados ao fornecimento de facilidades para aplicações”. Pontos de sincronização e o gerenciamento de atividades são os principais exemplos dessas facilidades.
Camada de Apresentação
A Camada de Apresentação é responsável pela tradução para um formato padronizado ex: JPEG, MP3, ASCII. Essa camada também é responsável pela criptografia e decifração com objetivos de segurança, bem como compressão de dados segundo (Tittel, 2003). Nela são fornecidos os serviços que podem ser selecionados posteriormente pela camada de aplicação com a finalidade de interpretar a sintaxe dos dados trocados, resolvendo problemas de diferença de sintaxe entre sistemas abertos.
Camada de Aplicação
Essa é a camada que fornece uma interface para os usuários e é responsável pela formatação dos dados antes que eles sejam passados para as camadas inferiores (McHOES, 2002). Podemos citar como exemplos comuns nessa camada o correio eletrônico e transferências de arquivos. Segundo Tanenbaum (2003, p.47), “A camada de aplicação contém uma série de protocolos comumente necessários para os usuários”.
Para Colcher (et al., 2005, p. 62), “Nesse nível são definidas funções de gerenciamento e mecanismos genéricos que servem de suporte à construção de aplicações distribuídas”.
Arquitetura TCP/IP
TCP/IP (Transmission Control Protocol / Internet Protocol) também chamado de pilha de protocolo TCP/IP, fornece um conjunto de serviços definidos para protocolos das camadas superiores. Segundo Colcher (et al., 2005, p. 70), “Os protocolos da Arquitetura TCP/IP, oferecem uma solução simples, porém bastante funcional, para o problema da interconexão de sistemas abertos”.
Assim como o modelo OSI, a Arquitetura TCP/IP é dividida em camada. A camada de Aplicação é correspondente às camadas 7, 6 e 5 do modelo OSI. A camada Host-to-host, espelha as funções da camada de transporte do modelo OSI. A camada de Rede, que corresponde a mesma camada de rede do modelo OSI, e por fim, a camada de Acesso à Rede, equivalente as camadas 1 e 2 do modelo OSI (FILLIPETTI, 2008).
Protocolo IP
O protocolo IP (Internet Protocol) definido pela RFC 791, conforme Postel (2002) é a base ou suporte para os outros protocolos da pilha TCP/IP, tais como ICMP, UDP e TCP, que são transmitidos em data gramas IP.
Uma característica deste protocolo é a possibilidade de fragmentar e remontar datagramas, de modo que estes possam ser transmitidos entre redes que suportem diferentes tamanhos por bloco de dados. Foi projetado para prover as funções necessárias para entregar pacotes de bits (datagramas IP) de uma origem para um destino determinado.
O protocolo IP é baseado na entrega de datagramas sem garantias, portanto inclui um conjunto de regras que dizem como hosts e gateways devem processar os datagramas, quando e como uma mensagem de erro deve ser gerada e as condições nas quais datagramas devem ser descartados (Comer, 2007). Ele incorpora também a função de roteamento, isto é, determina se um datagrama deve ser entregue diretamente a seu destino, caso origem e destino pertençam á mesma rede ou ao contrário entrega ao gateway da rede, contendo os dados do pacote de origem. Na figura 2 é ilustrada o cabeçalho IP.
Fonte: Stevens (1994, p. 34)
Endereçamento IPv4
O endereçamento IP, é uma identificação numérica atribuído a cada dispositivo conectado a uma rede IP, definindo para tal, uma localização na rede. No caso do IPv4 essa numeração tem o tamanho de 32 bits, onde a representação decimal é dividida em 4 blocos de 8 bits, o menor valor numérico em decimal de cada bloco é “0” e o maior igual à “255”, exemplo o endereço IP “72.247.64.170”.
Conforme Fillipetti (2008, p. 147), “A subdivisão de um endereço IP nas porções de rede e nó é determinada pela classe em que se encontra tal endereço”. Na figura 3, é ilustrada as cinco classes e os intervalos de endereços de cada uma.
Figura 3: Classe de endereços IP
Fonte: Fillipetti (2008, p. 147)
A divisão dos endereços IP’s em classes, facilita o processo de roteamento principalmente em grandes redes. A técnica consiste em verificar os primeiros dois bits do endereçamento, caso o primeiro bit for “0” o roteador tem a capacidade de encaminhar o pacote apenas com base nessa informação, sabendo-se que o endereço pertence à essa rede é de classe A, se for igual à “10” será de classe B e “11” classe C.
Entretanto, existem algumas faixas de numeração IP reservados, que não devem ser roteados na internet pública. Estas redes estão descritos na RFC 1918 (Address Allocation for Private Internets). A IANA (Internet Assigned Numbers Authority) tem reservado os seguintes blocos de IP para rede privada conforme a tabela 1.
| BLOCOS DE INTERVALOS | PREFIXO |
| 10.0.0.0 – 10.255.255.255 | 10/8 |
| 172.16.0.0 – 172.31.255.255 | 172.16/12 |
| 192.168.0.0 – 192.168.255.255 | 192.168/16 |
Fonte: Elaboração do Autor, 2010
Portanto, uma empresa ou organização que precise de um IP ou uma faixa de IP público global para ter acesso externo à Internet, nunca receberá endereços atribuídos às faixas mostradas acima. Os endereços de classe D são reservados para o uso de comunicação em Multicast.
O Multicast é um método para entrega de dados para múltiplos destinatários, em um modelo de um para vários. Para Costa (2006, p. “Quanto um pacote é enviado para um endereço Multicast, todos os host que fazem parte desse grupo Multicast receberão esse pacote”. Protocolos de roteamento usam esse método para descobrir roteadores pertencentes ao grupo na rede.
Protocolo ARP e RARP
O protocolo ARP (Address Resolution Protocol) definido pela RFC 826, conforme Torres (2001), foi projetado para interfaces do tipo 10 Mega bit Ethernet, mas foi generalizado para outros tipos de hardware. O módulo de resolução de endereços, normalmente parte do driver do dispositivo de hardware, recebe um par e tenta encontrá-lo em uma tabela. Se o par for encontrado, é retornado o endereço do hardware ou endereço físico correspondente para que o pacote possa ser transmitido. Caso contrário é normalmente informado que o pacote será descartado. Um exemplo comum na Internet é a utilização do ARP para converter endereços IP, de 32 bits, em endereços Ethernet, de 48 bits.
A função do protocolo RARP (Reverse Address Resolution Protocol) definido pela RFC 903, é inversa ao ARP, ou seja, converte um endereço de físicos em um endereço Internet. No momento da inicialização RARP é usado para encontrar o endereço Internet correspondente ao endereço de hardware do nó.
Protocolo ICMP
O protocolo ICMP (Internet Control Message Protocol) segundo Postel, (2002) tem como finalidade relatar erros no processamento de datagramas IP, bem como prover mecanismos de investigação nas características gerais de redes TCP/IP. O protocolo ICMP é definido na RFC 792.
As mensagens ICMP são enviadas em datagramas IP. Embora o ICMP pareça fazer parte do conjunto de protocolos de nível mais alto, este é parte da implementação do protocolo IP. O formato do cabeçalho de uma mensagem ICMP é apresentado na figura 4.
Figura 4: Formato de mensagens ICMP
Fonte: Stevens (1994, p. 70)
O protocolo UDP (User Datagram Protocol) Postel (2002) provê um mecanismo não orientado a conexão, ou seja, sem garantias, que através da utilização do protocolo IP, envia e recebe datagramas de uma aplicação para a outra. São utilizados números de portas para distinguir entre várias aplicações em um mesmo host, ou seja, cada mensagem UDP contém uma porta de origem e uma porta de destino.
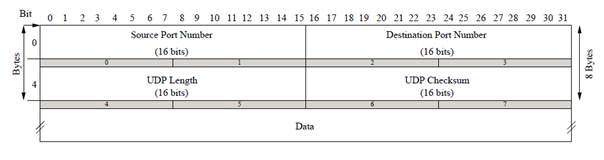
Uma aplicação baseada no protocolo UDP é inteiramente responsável por problemas de confiabilidade e problemas relacionados á conexão. Como isto normalmente não ocorre, este protocolo tem grande funcionalidade em ambientes locais e em aplicações que não requerem alta confiabilidade (Comer, 2007). Na figura 5 é demonstrada o modelo do cabeçalho UDP.
Figura 5: Modelo do Cabeçalho UDP
Fonte: Stevens (1994, p. 144)
Protocolo TCPFonte: Stevens (1994, p. 144)
O TCP (Transmission Control Protocol) conforme Postel (2002) é um protocolo de comunicação que provê conexões entre máquinas, de forma confiável, ou seja, é um protocolo orientado á conexão. Segundo Stevens (1994), o termo orientado á conexão "significa que duas aplicações, usando um protocolo que detém esta característica, devem estabelecer uma conexão bidirecional, antes de efetuar troca de dados”.
É considerado um protocolo confiável, pois quando um host envia dados a outro, o primeiro exige o reconhecimento relativo á chegada dos dados. Os dados são seqüenciados de forma que um número é associado a todo pacote transmitido, permitindo assim, que os dados sejam reordenados caso recebidos fora de ordem e descartando caso haja duplicações de pacotes já recebidos.
O controle de fluxo é uma característica importante, permitindo em uma conexão, que o host sempre informe ao outro quantos bytes poderão ser aceitos, evitando assim a ocorrências de sobrecargas do buffer do host que estiver recebendo dados (Stevens, 1994).
Figura 7: Modelo do cabeçalho TCP
Fonte: Stevens (1994, p. 225)
Fonte: Stevens (1994, p. 225)
Roteamento
O roteamento é a forma usada pelas redes de comutadores para realizar entrega de pacotes entre hosts (computadores, servidores, roteadores.), através de um conjunto de regras que definem como dados originados em uma determinada sub-rede devem alcançar outra. De uma forma geral a internet é uma teia de roteadores interligados onde cada um é responsável por entregar o pacote (caso o destino esteja em sua rede) ou encaminhar ao próximo roteador.
Conforme Tittel (2003) o roteador precisa primeiramente saber quantas portas físicas (ethernet, serial, bri, pri..) e quais são os endereços de rede configurado em cada uma delas. Essas informações são fundamentais para o roteador montar sua tabela de roteamento e saber se o pacote que está sendo processado está ou não em sua rede.
As formas de roteamento mais comum dentre os roteadores de ponta ou CE é o estático e entre os roteadores de borda PE e de núcleo P os dinâmicos. O roteamento dinâmico é dividido em IGP (Interior Gateway Protocol) e EGP (Exterior Gateway Protocol) que serão abordados nos próximos tópicos.
Roteamento Estático
Esse tipo de roteamento é usado pelo administrador quando se tem o conhecimento das redes nos quais os pacotes vão atingir. Tendo em vista que essa modalidade não se adapta á mudanças da rede, são geralmente usados em ponta de rede (cliente) ou em redes com poucos roteadores. Os valores tais como: rede, máscara de destino, gateway e custo, são configurados manualmente no roteador, onde os pacotes seguiram sempre a regra.
Segundo Comer (2007) nesse tipo de roteamento, uma tabela de roteamento estática é preenchida com valores quando o sistema é inicializado e elas só mudaram se o sistema vir á apresentar defeito. Essas tabelas são usadas para determinar para onde cada pacote deve ser encaminhado.
Os principais benefícios do roteamento estático são: redução de overhead, não utiliza largura de banda, já que não troca informações de roteamento e segurança, uma vez que o administrador possui o controle do processo de roteamento.
Roteamento Dinâmico
Para uma pequena rede ou em redes onde não há constantes mudanças, o roteamento estático pode ser usado, configurando manualmente cada uma das rotas. Já em redes maiores, configurar cada uma das rotas não é uma boa opção para o administrador. Em grandes redes normalmente é utilizado protocolos de roteamento dinâmicos, fazendo com que os roteadores troquem informações sobre roteamento e se adaptem melhor as mudanças de rede caso alguma eventualidade aconteça.
Segundo Filippetti (2008) o processo de roteamento dinâmico utiliza protocolos para encontrar e atualizar tabelas de roteamento de roteadores. Esse modo é muito mais fácil comparado ao roteamento estático, porém consome largura de banda e processamento da CPU do equipamento. Os protocolos de roteamento dinâmicos são classificados como: vetor á distância, link state e híbrido.
Protocolos de Roteamento Distance Vector
São classificados nessa categoria os protocolos de roteamento que utilizam distância à rede remota como métrica para a escolha caminho. É definido como a melhor rota aquela que conter o menor número de saltos ou hops como é chamada, até a rede remota, ou seja, são protocolos que se baseiam na contagem de saltos para definir a escolha da melhor rota. Exemplos de protocolos que pertencem a essa classe são RIP (Route Information Protocol) e IGRP (Interior Gateway Routing Protocol).
O funcionamento dos protocolos vetor á distância consiste em enviar as tabelas de roteamento aos roteadores vizinhos, combinando essas com outras que já possuem, montando um mapa da rede (Filippetti, 2008). Em caso de uma rede possuir vários links para uma mesma rede remota a distância administrativa é o primeiro fator a ser checado para definir a rota preferencial.
O RIP utiliza apenas a contagem de saltos (hop count) para determinação da melhor rota para uma rede remota. Se o RIP deparar-se com mais de um link para a mesma rede remota com a mesma contagem de saltos, ele executará automaticamente o que chamamos de round-robin load balance, ou seja, distribuirá alternadamente a carga entre os links de igual custo (mesmo número de saltos no caso). O RIP pode realizar balanceamento de carga para até 6 links com mesmo custo. (Filippetti 2008, p. 253)
Nesse caso pode ser uma solução ou um problema, já que o balanceamento entre os links será efetuado independentemente da velocidade de banda, ocasionando problemas de congestionamento quando a velocidade entre os links for diferente.
Outro exemplo é o IGRP (Interior Gateway Routing Protocol) segundo Enne (2009, p. 26), “É um protocolo proprietário definido pela CISCO Systems e representa a evolução do RIP, operando também distance vector”.
Protocolos de Roteamento Link-State
Os protocolos de roteamento link state são protocolos baseados no algoritmo Dijkstra SPF (Shortest Path First). Utilizado principalmente para comunicação dentro de um domínio de roteamento ou uma AS, esse algoritmo produz mais informações locais (dentro do próprio equipamento) sem a necessidade de ficar coletando informações sobre o estado da rede a todo o momento, os anúncios são feitos somente quando há mudança na rede, reduzindo assim o consumo de banda. Em contrapartida, esse tipo de roteamento eleva muito a carga de processamento, aconselhado, antes de implementá-lo, verificar se o hardware irá suportar tal demanda.
Os Protocolos de roteamento link state mantêm registro de todas as rotas possíveis para evitar alguns problemas típicos de protocolos vetor à distância como loops de roteamento. Os protocolos mais utilizados que se baseiam na tecnologia link-state são OSPF e IS-IS.
O OSPF (Open Shortest Path First) definido na versão atual pela RFC 2328, é um protocolo do tipo IGP projetado para trabalhar em grandes redes, atendendo as necessidades das nuvens públicas e privadas. O protocolo OSPF veio atender operadoras que demandavam de um protocolo IGP eficiente, versátil, de rápida convergência, interoperável com outros protocolos de roteamento e não proprietário, assim podendo ser incorporado a equipamentos de qualquer fabricante.
Trabalha com conceito de áreas ou grupo de roteadores que compartilham o mesmo ID de áreas. Segundo Brent (2008), o algoritmo Dijkstra SPF é usado para calcular o melhor caminho para o destino construindo caminhos sem loops com capacidade de convergência muito rápida. Habilitado nos roteadores, o OSPF constrói adjacências ao enviar pacotes hello através das interfaces. Os pacotes hello são responsáveis pela descoberta, estabelecimento e manutenção de relações entre roteadores vizinhos e são disparados pelo endereço multicast 224.0.0.5. Os roteadores que compartilharem um link comum e aceitarem os parâmetros dos pacotes hello, tornam-se vizinhos formando adjacências, caso contrário a negociação é desfeita. Assim que as adjacências são formadas, é envia uma LSA (Link State Advertisements) para os roteadores adjacentes. LSA´s são datagramas que descrevem os status de cada link e o estado de cada roteador, existem LSA para cada tipo de link.
Conforme Fillipetti (2008), o OSPF utiliza de mecanismos para eleger um DR (Designated Router) e um BDR (Backup Designated Router).
O Roteador DR é responsável por estabelecer adjacências com todos os vizinhos, enquanto o BDR fica de backup caso o DR venho à falhar, assumindo todas as suas funções. O escolha do roteador DR é determinada pelo maior valor de prioridade configurada. No caso das prioridades estarem configuradas com mesmo valor, a escolha do DR é feita pelo maior valor de IP da interface ativa e a segunda maior será o BDR, dando sempre preferência para os endereços das interfaces loopback. O endereço multicast 224.0.0.6 é usado para enviar informações ao DR, o BRD também recebe pacotes nesse endereço mais de maneira passiva.
Logo após todo o banco de dados da área correspondente rede estiver completo, cada roteador executa o algoritmo SPF e constrói sua tabela de roteamento formando a topologia da rede. Com base nesses cálculos os roteadores constroem suas link-state databese, onde fica armazenado o mapa completo de todos os roteadores, seus links e o estado de cada link. Muito utilizado em redes de alta performance, o OSPF é fundamental para empresas que busca desempenho em equipamentos que comportam grande capacidade de processamento.
O protocolo IS-IS (Intermediate System to Intermediate System) definido pela RFC 1142, é um outro exemplo de protocolo link-state tipo IGP, conhecido também como protocolo intra-domínio. É comumente usado para interligar roteadores em áreas distintas ou em mesma área, utiliza o algoritmo Dijkstra SPF com suporte a VLSM (Variable Length Subnet Mask) e rápida convergência assim como o OSPF. IS-SI e OSPF têm mais semelhanças do que diferenças. Ambos os protocolos foram desenvolvidos em torno do mesmo propósito, porém, entre os protocolos IGP, o OSPF é mais usado no momento (Enne, 2009).
Protocolo BGP
O BGP (Border Gateway Protocol) é um protocolo tipo EGP de maior utilização no momento. Para Enne (2009. p. 31) “É o protocolo distance vetor, baseado no paradigma que considera apenas os endereços de destino ou os prefixos dos endereços de destino como referência para roteamento e no número de hops atravessados para alcançar esses destinos”. O BGP é um protocolo de roteamento moderno e extremamente complexo, projetado para escalar as maiores redes e criar rotas estável entre elas, com suporte para comprimento variável máscara de sub-rede VLSM (Variable Length Subnet Mask) e roteamento intra-domínios sem classe CIDR (Classless Inter-Domain Routing) e compactação.
Na versão atual definida pela RFC 4271, o BGP é um amplamente difundido em toda a Internet e dentro de organizações multinacionais. Seu principal objetivo é conectar as grandes redes identificadas por uma AS (Autônomous Systems) ou sistemas autônomos. Um AS é uma rede ou um conjunto de redes que além de compartilharem uma gestão comum, possuem características e políticas de roteamento comuns. Utilizadas em protocolos de roteamento dinâmicos tipo EGP, servem para comunicar com outros equipamentos dentro de uma mesma AS e inter-AS.
No funcionamento básico, o BGP obtém as rotas referentes às redes pertencentes a uma AS, onde internamente são conduzidas por protocolos tipo IGP, e repassam para roteados BGPs vizinhos.
Considerando que os IGPs buscam as informações mais recentes que estão constantemente ajustando as rotas com base em novas informações, o BGP foi projetado para dar preferência as rotas mais estáveis e não constantemente renunciando. Além disso, configurações BGP normalmente requerem decisões políticas complexas. Assim, dado esta complexidade associada ao tamanho extremo da tabela de roteamento (muitas vezes centenas de milhares de rotas), não é surpreendente que as rotas que ficam constantemente ajustando poderiam sobrecarregar o BGP. (Brent, 2008, p. 399).
Conforme Enne (2009), o BGP utiliza o protocolo TCP para transporte as mensagens, aproveitando algumas facilidades nele contidas. Existem quatro tipos de mensagens BGP utilizados na formação de relacionamento entre vizinhos e manutenção: OPEN, KEEPALIVE, UPDATE e NOTIFICATION, onde começam a ser trocadas logo após o estabelecimento das conexões TCP.
Quando iniciado um processo BGP, ele cria ligações através de mensagens BGP OPEN e se aceitas, obtém uma resposta com KEEPALIVE. Estabelecido pela primeira vez, os roteadores BGP trocam suas tabelas de roteamento completas utilizando mensagens de UPDATE e posteriormente, enviadas quando houver alguma mudança na rede. Mensagens NOTIFICATION são enviadas para notificar algum erro, nessas condições, conexões BGP são encerradas imediatamente.
As rotas são controladas à medida que atravessam os roteadores BGP para evitar loops de roteamento. Consiste em rejeitar as rotas que já passaram por sua AS. A cada salto do pacote, é inserido o número da AS em AS-path, conforme a figura abaixo.
Figura 8: Uso de AS-Path para detecção de loops BGP
Fonte: Brent (2008, p. 400)
Última edição por Felipe Marques em Sáb 11 maio - 9:46, editado 9 vez(es)